
小伙伴们通过订阅微信公众账号,实现动态获取荤素搭配的英文段子的功能。
1. 注册微信公共账号
记住你填写的 Token 值,下面发请求的时候要用。
2. 新建 Django 工程
在正式对接之前,微信会发送验证请求,那么首先我们要通过微信的认证。
@csrf_exempt
def handleRequest(request):
if request.method == 'GET':
isDebug = request.GET.get("debug", False)
if isDebug:
response = HttpResponse(getJoke(), content_type="application/xml")
else:
response = HttpResponse(checkSignature(request), content_type="text/plain")
return response
elif request.method == 'POST':
response = HttpResponse(responseJoke(request), content_type="application/xml")
return response
else:
return Nonedef checkSignature(request):
global TOKEN
signature = request.GET.get("signature", None)
timestamp = request.GET.get("timestamp", None)
nonce = request.GET.get("nonce", None)
echoStr = request.GET.get("echostr",None)
token = TOKEN
tmpList = [token,timestamp,nonce]
tmpList.sort()
tmpstr = "%s%s%s" % tuple(tmpList)
tmpstr = hashlib.sha1(tmpstr).hexdigest()
if tmpstr == signature:
return echoStr
else:
return None这里的 TOKEN 填正确就可以。
3. Get A Joke
扒了一个 jokes.com 的 api 出来。第一次请求会请求 joke 的 url,第二次请求这个 url,返回页面数据。
def getJoke():
url = "http://www.jokes.com/feeds/random/" + str(random.randint(1,6000))
print "oriurl = %s" % url
requestHeader = {
# 'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.65 Safari/537.36',
# 'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language':'zh-CN,zh;q=0.8,en;q=0.6',
# 'Connection':'keep-alive',
# 'Cookie':'btg_device=m:0,t:0; vmn_poe=6x6; vmn_3pc=1; vmn_uuid=83e641be-f169-b37d-0366-77b7032dfcde; mtvn_guid=83e641be-f169-b37d-0366-77b7032dfcde; mtvn_btg_userSegments=GoogleUser; vmn_host=1; __qca=P0-201743870-1379076006026; mtvn_dmp_init=1; s_ppv=54; s_nr=1379077134612; s_cc=true; s_fid=4D6188E19068AD91-016FE58ECD5F9736; s_sq=%5B%5BB%5D%5D; FluxLoadCounter4CFAFFFF009922C10002FFFFFA4C=22',
# 'Host':'www.jokes.com'
}
requestTimeout = 5
# proxy = urllib2.ProxyHandler({'http':'192.168.2.59:8080'})
# opener = urllib2.build_opener(proxy)
# urllib2.install_opener(opener)
requestBody = urllib2.Request(url, None, requestHeader)
dataJson = json.loads(urllib2.urlopen(requestBody, None, requestTimeout).read())
print "jokeurl = %s" % dataJson['0']['url']
jokeUrl = dataJson['0']['url']
requestBody = urllib2.Request(jokeUrl, None, requestHeader)
data = urllib2.urlopen(requestBody, None, requestTimeout).read()
print "data = %s" % data
patten = re.compile(r"""<meta\s.*?\s?name="description"\s.*?\s?content\s*=\s*"([\s\S]*?)"\s/>""")
joke = (re.findall(patten, data))[0];
joke = HTMLParser.HTMLParser().unescape(joke)
print "joke = %s" % joke
return joke4. 该返回给小伙伴们了
def responseJoke(request):
rawStr = smart_str(request.raw_post_data)
msg = paraseMsgXml(ET.fromstring(rawStr))
replyContent = getJoke()
return getReplyXml(msg,replyContent)def getReplyXml(msg, replyContent):
extTpl = "<xml><ToUserName><![CDATA[%s]]></ToUserName><FromUserName><![CDATA[%s]]></FromUserName><CreateTime>%s</CreateTime><MsgType><![CDATA[%s]]></MsgType><Content><![CDATA[%s]]></Content><MsgId>1234567890123456</MsgId></xml>";
extTpl = extTpl % (msg['FromUserName'],msg['ToUserName'],str(int(time.time())),'text',replyContent)
return extTpl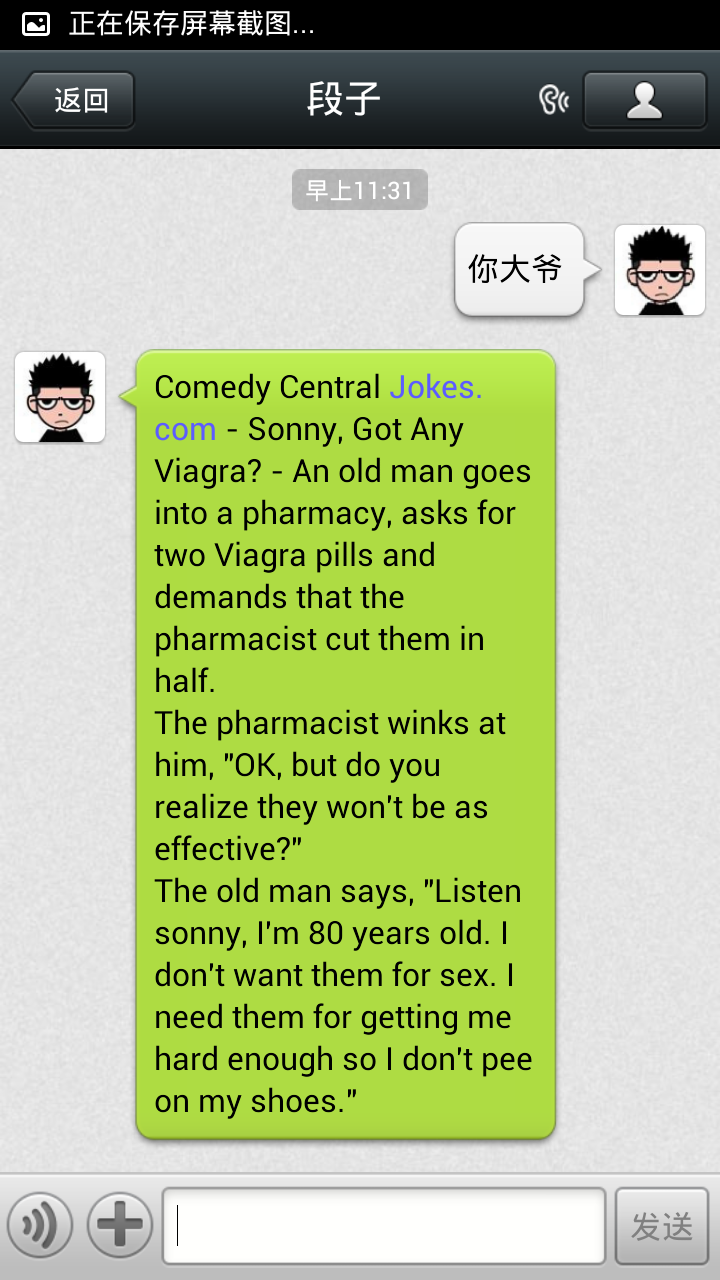
我的微信公众账号是 tinyjoke,或者扫一扫

